Quickstart¶
Installation¶
pip install pyspider- run command
pyspider, visit http://localhost:5000/
if you are using ubuntu, try:
apt-get install python python-dev python-distribute python-pip \
libcurl4-openssl-dev libxml2-dev libxslt1-dev python-lxml \
libssl-dev zlib1g-dev
to install binary packages first.
please install PhantomJS if needed: http://phantomjs.org/build.html
note that PhantomJS will be enabled only if it is excutable in the PATH or in the System Environment
Note: pyspider command is running pyspider in all mode, which running components in threads or subprocesses. For production environment, please refer to Deployment.
WARNING: WebUI is opened to public by default, it can be used to execute any command which may harm to you system. Please use it in internal network or enable need-auth for webui.
Your First Script¶
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
def on_start(self)is the entry point of the script. It will be called when you click therunbutton on dashboard.self.crawl(url, callback=self.index_page)* is the most important API here. It will add a new task to be crawled. Most of the options will be spicified viaself.crawlarguments.def index_page(self, response)get aResponse* object.response.doc* is a pyquery object which has jQuery-like API to select elements to be extracted.def detail_page(self, response)return adictobject as result. The result will be captured intoresultdbby default. You can overrideon_result(self, result)method to manage the result yourself.
More things you may want to know:
@every(minutes=24*60, seconds=0)* is a helper to tell the scheduler thaton_startmethod should be called everyday.@config(age=10 * 24 * 60 * 60)* specified the defaultageparameter ofself.crawlwith page typeindex_page(whencallback=self.index_page). The parameterage* can be specified viaself.crawl(url, age=10*24*60*60)(highest priority) andcrawl_config(lowest priority).age=10 * 24 * 60 * 60* tell scheduler discard the request if it have been crawled in 10 days. pyspider will not crawl a same URL twice by default (discard forever), even you had modified the code, it's very common for beginners that runs the project the first time and modified it and run it the second time, it will not crawl again (readitagfor solution)@config(priority=2)* mark that detail pages should be crawled first.
You can test your script step by step by click the green run button. Switch to follows panel, click the play button to move on.
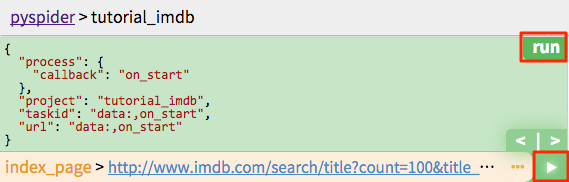
Start Running¶
- Save your script.
- Back to dashboard find your project.
- Changing the
statustoDEBUGorRUNNING. - Click the
runbutton.
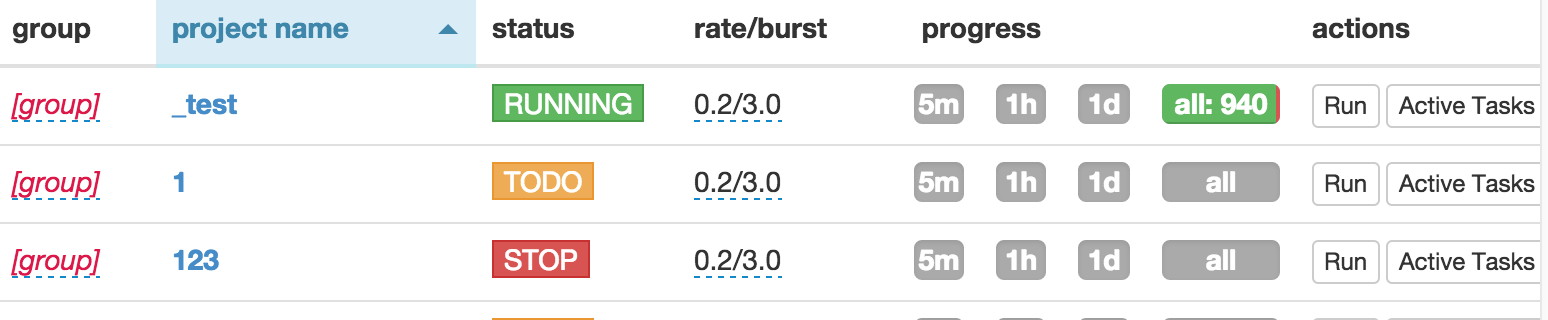
Your script is running now!